Python
Python correlation and regression
––– views
The Boston Housing Dataset
The Boston Housing Dataset is a derived from information collected by the U.S. Census Service concerning housing in the area of Boston MA. The following describes the dataset columns:
- CRIM - per capita crime rate by town
- ZN - proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS - proportion of non-retail business acres per town.
- CHAS - Charles River dummy variable (1 if tract bounds river; 0 otherwise)
- NOX - nitric oxides concentration (parts per 10 million)
- RM - average number of rooms per dwelling
- AGE - proportion of owner-occupied units built prior to 1940
- DIS - weighted distances to five Boston employment centres
- RAD - index of accessibility to radial highways
- TAX - full-value property-tax rate per $10,000
- PTRATIO - pupil-teacher ratio by town
- B - 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT - % lower status of the population
- MEDV - Median value of owner-occupied homes in $1000's
Load Packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns; sns.set(style='white', color_codes=True)
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')Import csv from Local Machine
names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
df=pd.read_csv('housing.csv', delim_whitespace=True,names=names)df.head() CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX \
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296.0
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242.0
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242.0
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222.0
4 0.06905 0.0 2.18 0 0.458 7.147 54.2 6.0622 3 222.0
PTRATIO B LSTAT MEDV
0 15.3 396.90 4.98 24.0
1 17.8 396.90 9.14 21.6
2 17.8 392.83 4.03 34.7
3 18.7 394.63 2.94 33.4
4 18.7 396.90 5.33 36.2Basic Information
df.shape (506, 14)df.info() <class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CRIM 506 non-null float64
1 ZN 506 non-null float64
2 INDUS 506 non-null float64
3 CHAS 506 non-null int64
4 NOX 506 non-null float64
5 RM 506 non-null float64
6 AGE 506 non-null float64
7 DIS 506 non-null float64
8 RAD 506 non-null int64
9 TAX 506 non-null float64
10 PTRATIO 506 non-null float64
11 B 506 non-null float64
12 LSTAT 506 non-null float64
13 MEDV 506 non-null float64
dtypes: float64(12), int64(2)
memory usage: 55.5 KBdf.describe() CRIM ZN INDUS CHAS NOX RM \
count 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000
mean 3.613524 11.363636 11.136779 0.069170 0.554695 6.284634
std 8.601545 23.322453 6.860353 0.253994 0.115878 0.702617
min 0.006320 0.000000 0.460000 0.000000 0.385000 3.561000
25% 0.082045 0.000000 5.190000 0.000000 0.449000 5.885500
50% 0.256510 0.000000 9.690000 0.000000 0.538000 6.208500
75% 3.677082 12.500000 18.100000 0.000000 0.624000 6.623500
max 88.976200 100.000000 27.740000 1.000000 0.871000 8.780000
AGE DIS RAD TAX PTRATIO B \
count 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000
mean 68.574901 3.795043 9.549407 408.237154 18.455534 356.674032
std 28.148861 2.105710 8.707259 168.537116 2.164946 91.294864
min 2.900000 1.129600 1.000000 187.000000 12.600000 0.320000
25% 45.025000 2.100175 4.000000 279.000000 17.400000 375.377500
50% 77.500000 3.207450 5.000000 330.000000 19.050000 391.440000
75% 94.075000 5.188425 24.000000 666.000000 20.200000 396.225000
max 100.000000 12.126500 24.000000 711.000000 22.000000 396.900000
LSTAT MEDV
count 506.000000 506.000000
mean 12.653063 22.532806
std 7.141062 9.197104
min 1.730000 5.000000
25% 6.950000 17.025000
50% 11.360000 21.200000
75% 16.955000 25.000000
max 37.970000 50.000000#df.isna() #will return True or False for each value, if null then True, if not null then False
df.isna().sum() #will return total number of null for each column CRIM 0
ZN 0
INDUS 0
CHAS 0
NOX 0
RM 0
AGE 0
DIS 0
RAD 0
TAX 0
PTRATIO 0
B 0
LSTAT 0
MEDV 0
dtype: int64Exploratory Data Analysis
df.hist(bins='auto', grid=False, figsize=(20,15), color='#86bf91', zorder=2, rwidth=0.9)
plt.show()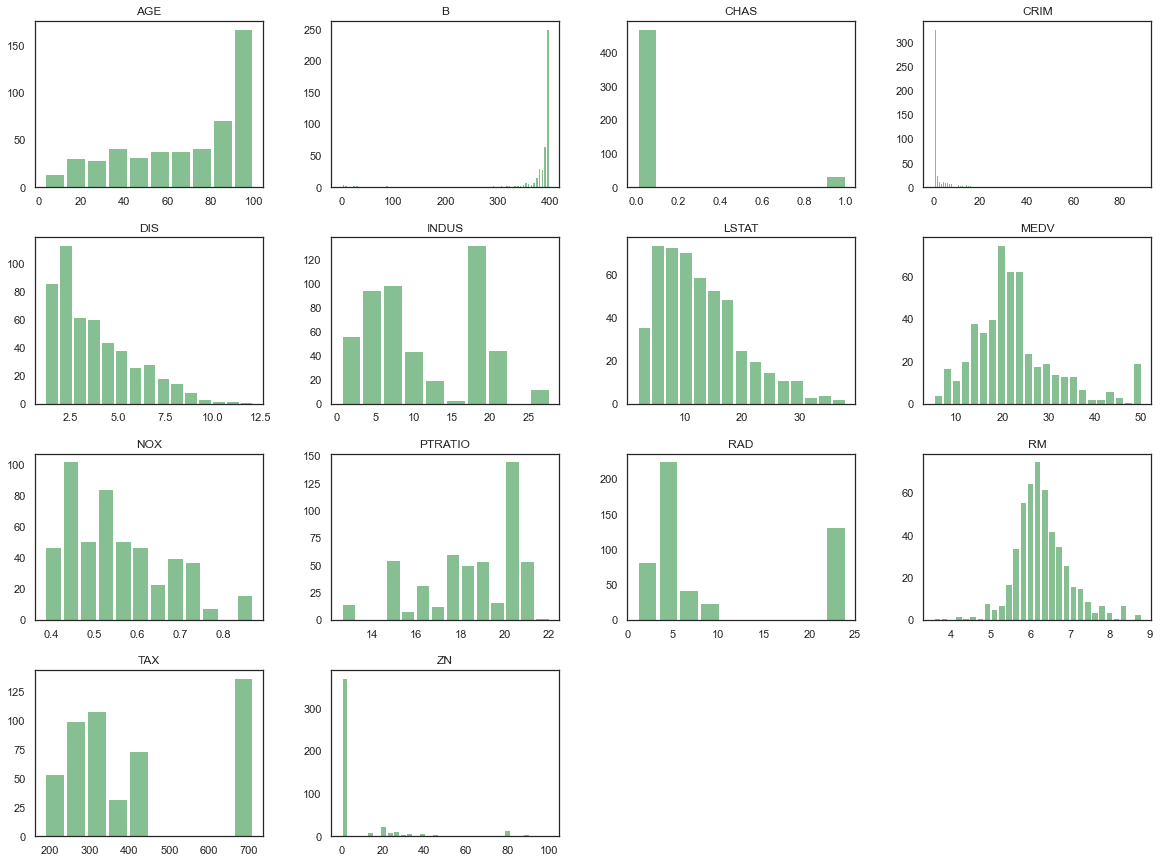
sns.pairplot(df) <seaborn.axisgrid.PairGrid at 0x1c389a3ed60>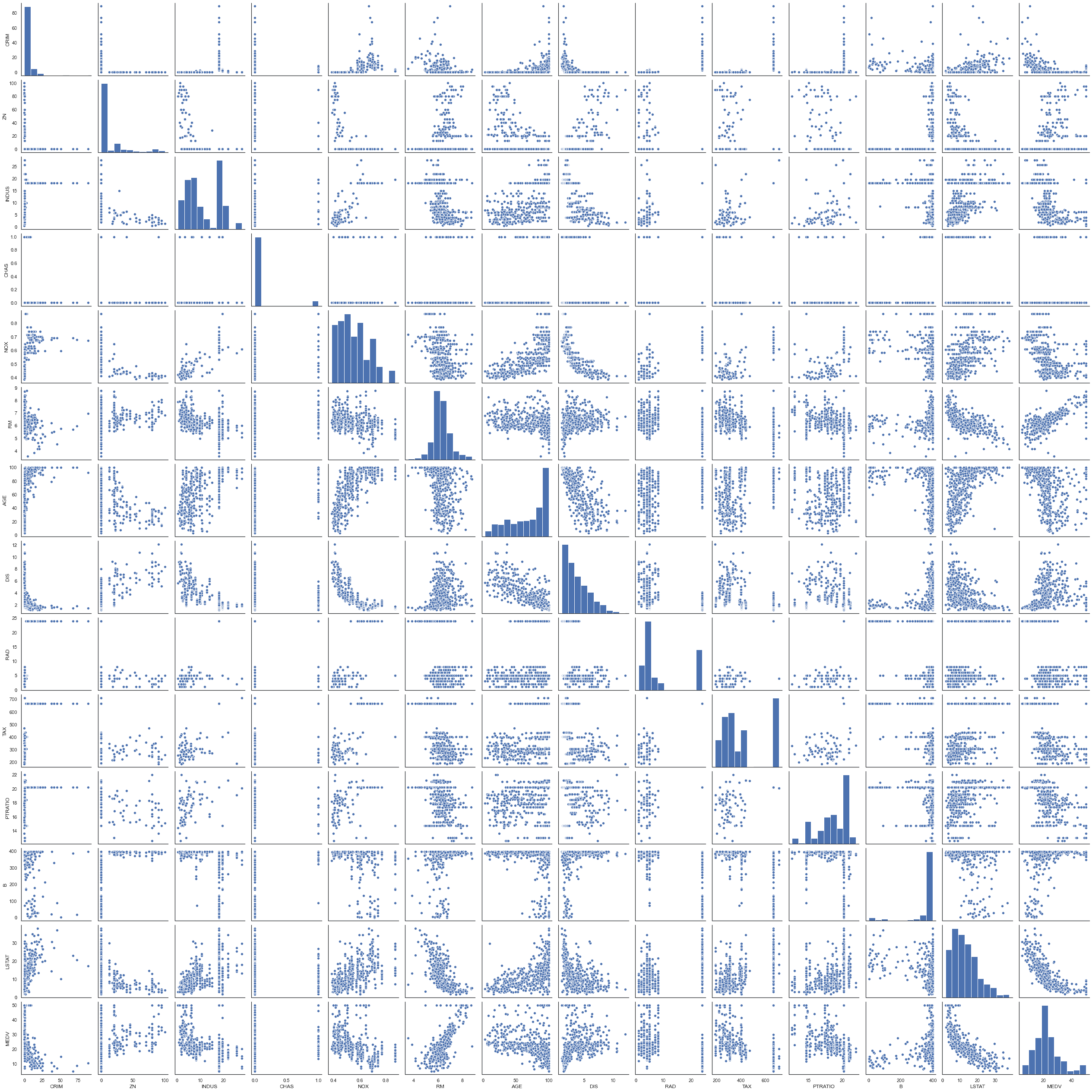
plt.hist(df['MEDV'])
plt.show()
l=sns.lmplot(data=df,x='CRIM',y='MEDV',size=7,aspect=1,scatter_kws={"s":100})
Correlation
df.corr() CRIM ZN INDUS CHAS NOX RM AGE \
CRIM 1.000000 -0.200469 0.406583 -0.055892 0.420972 -0.219247 0.352734
ZN -0.200469 1.000000 -0.533828 -0.042697 -0.516604 0.311991 -0.569537
INDUS 0.406583 -0.533828 1.000000 0.062938 0.763651 -0.391676 0.644779
CHAS -0.055892 -0.042697 0.062938 1.000000 0.091203 0.091251 0.086518
NOX 0.420972 -0.516604 0.763651 0.091203 1.000000 -0.302188 0.731470
RM -0.219247 0.311991 -0.391676 0.091251 -0.302188 1.000000 -0.240265
AGE 0.352734 -0.569537 0.644779 0.086518 0.731470 -0.240265 1.000000
DIS -0.379670 0.664408 -0.708027 -0.099176 -0.769230 0.205246 -0.747881
RAD 0.625505 -0.311948 0.595129 -0.007368 0.611441 -0.209847 0.456022
TAX 0.582764 -0.314563 0.720760 -0.035587 0.668023 -0.292048 0.506456
PTRATIO 0.289946 -0.391679 0.383248 -0.121515 0.188933 -0.355501 0.261515
B -0.385064 0.175520 -0.356977 0.048788 -0.380051 0.128069 -0.273534
LSTAT 0.455621 -0.412995 0.603800 -0.053929 0.590879 -0.613808 0.602339
MEDV -0.388305 0.360445 -0.483725 0.175260 -0.427321 0.695360 -0.376955
DIS RAD TAX PTRATIO B LSTAT MEDV
CRIM -0.379670 0.625505 0.582764 0.289946 -0.385064 0.455621 -0.388305
ZN 0.664408 -0.311948 -0.314563 -0.391679 0.175520 -0.412995 0.360445
INDUS -0.708027 0.595129 0.720760 0.383248 -0.356977 0.603800 -0.483725
CHAS -0.099176 -0.007368 -0.035587 -0.121515 0.048788 -0.053929 0.175260
NOX -0.769230 0.611441 0.668023 0.188933 -0.380051 0.590879 -0.427321
RM 0.205246 -0.209847 -0.292048 -0.355501 0.128069 -0.613808 0.695360
AGE -0.747881 0.456022 0.506456 0.261515 -0.273534 0.602339 -0.376955
DIS 1.000000 -0.494588 -0.534432 -0.232471 0.291512 -0.496996 0.249929
RAD -0.494588 1.000000 0.910228 0.464741 -0.444413 0.488676 -0.381626
TAX -0.534432 0.910228 1.000000 0.460853 -0.441808 0.543993 -0.468536
PTRATIO -0.232471 0.464741 0.460853 1.000000 -0.177383 0.374044 -0.507787
B 0.291512 -0.444413 -0.441808 -0.177383 1.000000 -0.366087 0.333461
LSTAT -0.496996 0.488676 0.543993 0.374044 -0.366087 1.000000 -0.737663
MEDV 0.249929 -0.381626 -0.468536 -0.507787 0.333461 -0.737663 1.000000plt.figure(figsize=(20, 10))
sns.heatmap(df.corr(),
annot=True
,center=0, cmap=sns.diverging_palette(20, 220, n=256, as_cmap=True) #Gradient color (optional)
) <matplotlib.axes._subplots.AxesSubplot at 0x1c391c76d00>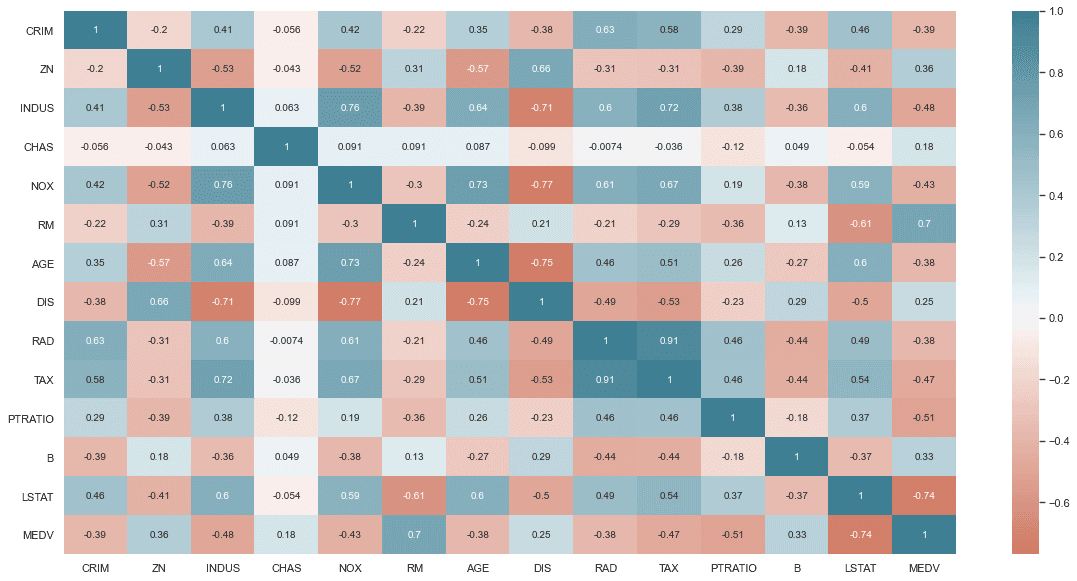
Linear Regression Model
Linear Regression using Statsmodels
import statsmodels.api as sm
from statsmodels.graphics.gofplots import ProbPlotdf.columns Index(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT', 'MEDV'],
dtype='object')#Multiple linear regression (Select single variable for simple linear regression)
X = df[['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT']]
#x = df.loc[:, df.columns != 'MEDV'] #Same as above but more convenient
#X = df[['CRIM', 'ZN']] #Omit insignificant variable
y = df['MEDV'] #Target or dependend VariableX = sm.add_constant(X) #interceptmodel = sm.OLS(y, X).fit() #Ordinary least Square #trained modelpredictions = model.predict(X)
#predictionsmodel.summary() <class 'statsmodels.iolib.summary.Summary'>
"""
OLS Regression Results
==============================================================================
Dep. Variable: MEDV R-squared: 0.741
Model: OLS Adj. R-squared: 0.734
Method: Least Squares F-statistic: 108.1
Date: Wed, 02 Dec 2020 Prob (F-statistic): 6.72e-135
Time: 12:46:46 Log-Likelihood: -1498.8
No. Observations: 506 AIC: 3026.
Df Residuals: 492 BIC: 3085.
Df Model: 13
Covariance Type: nonrobust
==============================================================================
coef std err t ----------------------------------
const 36.4595 5.103 7.144 0.000 26.432 46.487
CRIM -0.1080 0.033 -3.287 P>|t| [0.025 0.975]
-------------------------------------------- 0.001 -0.173 -0.043
ZN 0.0464 0.014 3.382 0.001 0.019 0.073
INDUS 0.0206 0.061 0.334 0.738 -0.100 0.141
CHAS 2.6867 0.862 3.118 0.002 0.994 4.380
NOX -17.7666 3.820 -4.651 0.000 -25.272 -10.262
RM 3.8099 0.418 9.116 0.000 2.989 4.631
AGE 0.0007 0.013 0.052 0.958 -0.025 0.027
DIS -1.4756 0.199 -7.398 0.000 -1.867 -1.084
RAD 0.3060 0.066 4.613 0.000 0.176 0.436
TAX -0.0123 0.004 -3.280 0.001 -0.020 -0.005
PTRATIO -0.9527 0.131 -7.283 0.000 -1.210 -0.696
B 0.0093 0.003 3.467 0.001 0.004 0.015
LSTAT -0.5248 0.051 -10.347 0.000 -0.624 -0.425
==============================================================================
Omnibus: 178.041 Durbin-Watson: 1.078
Prob(Omnibus): 0.000 Jarque-Bera (JB): 783.126
Skew: 1.521 Prob(JB): 8.84e-171
Kurtosis: 8.281 Cond. No. 1.51e+04
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.51e+04. This might indicate that there are
strong multicollinearity or other numerical problems.
"""# print the coefficients
model.params const 36.459488
CRIM -0.108011
ZN 0.046420
INDUS 0.020559
CHAS 2.686734
NOX -17.766611
RM 3.809865
AGE 0.000692
DIS -1.475567
RAD 0.306049
TAX -0.012335
PTRATIO -0.952747
B 0.009312
LSTAT -0.524758
dtype: float64model.pvalues const 3.283438e-12
CRIM 1.086810e-03
ZN 7.781097e-04
INDUS 7.382881e-01
CHAS 1.925030e-03
NOX 4.245644e-06
RM 1.979441e-18
AGE 9.582293e-01
DIS 6.013491e-13
RAD 5.070529e-06
TAX 1.111637e-03
PTRATIO 1.308835e-12
B 5.728592e-04
LSTAT 7.776912e-23
dtype: float64model.rsquared 0.7406426641094094model.conf_int() 0 1
const 26.432226 46.486751
CRIM -0.172584 -0.043438
ZN 0.019449 0.073392
INDUS -0.100268 0.141385
CHAS 0.993904 4.379563
NOX -25.271634 -10.261589
RM 2.988727 4.631004
AGE -0.025262 0.026647
DIS -1.867455 -1.083679
RAD 0.175692 0.436407
TAX -0.019723 -0.004946
PTRATIO -1.209795 -0.695699
B 0.004034 0.014589
LSTAT -0.624404 -0.425113Residuals vs Fitted
# model values
model_fitted_y = model.fittedvalues
# model residuals
model_residuals = model.resid
# normalized residuals
model_norm_residuals = model.get_influence().resid_studentized_internal
# absolute squared normalized residuals
model_norm_residuals_abs_sqrt = np.sqrt(np.abs(model_norm_residuals))
# absolute residuals
model_abs_resid = np.abs(model_residuals)
# leverage, from statsmodels internals
model_leverage = model.get_influence().hat_matrix_diag
# cook's distance, from statsmodels internals
model_cooks = model.get_influence().cooks_distance[0]
plot_lm_1 = plt.figure()
plot_lm_1.axes[0] = sns.residplot(model_fitted_y, df.columns[-1], data=df,
lowess=True,
scatter_kws={'alpha': 0.5},
line_kws={'color': 'red', 'lw': 1, 'alpha': 0.8})
plot_lm_1.axes[0].set_title('Residuals vs Fitted')
plot_lm_1.axes[0].set_xlabel('Fitted values')
plot_lm_1.axes[0].set_ylabel('Residuals');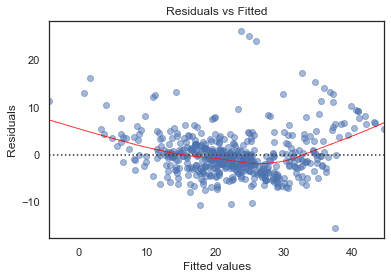
Normal Q-Q Plot
QQ = ProbPlot(model_norm_residuals)
plot_lm_2 = QQ.qqplot(line='45', alpha=0.5, color='#4C72B0', lw=1)
plot_lm_2.axes[0].set_title('Normal Q-Q')
plot_lm_2.axes[0].set_xlabel('Theoretical Quantiles')
plot_lm_2.axes[0].set_ylabel('Standardized Residuals');
# annotations
abs_norm_resid = np.flip(np.argsort(np.abs(model_norm_residuals)), 0)
abs_norm_resid_top_3 = abs_norm_resid[:3]
for r, i in enumerate(abs_norm_resid_top_3):
plot_lm_2.axes[0].annotate(i,
xy=(np.flip(QQ.theoretical_quantiles, 0)[r],
model_norm_residuals[i]));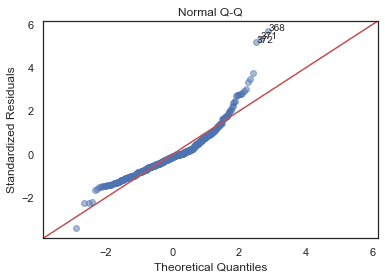
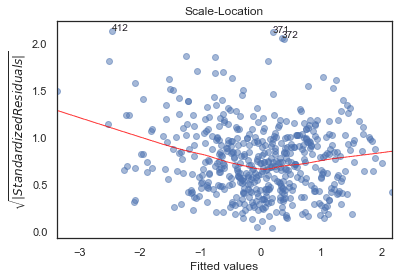
Scale-Location
plot_lm_3 = plt.figure()
plt.scatter(model_fitted_y, model_norm_residuals_abs_sqrt, alpha=0.5);
sns.regplot(model_fitted_y, model_norm_residuals_abs_sqrt,
scatter=False,
ci=False,
lowess=True,
line_kws={'color': 'red', 'lw': 1, 'alpha': 0.8});
plot_lm_3.axes[0].set_title('Scale-Location')
plot_lm_3.axes[0].set_xlabel('Fitted values')
plot_lm_3.axes[0].set_ylabel('$\sqrt{|Standardized Residuals|}$');
# annotations
abs_sq_norm_resid = np.flip(np.argsort(model_norm_residuals_abs_sqrt), 0)
abs_sq_norm_resid_top_3 = abs_sq_norm_resid[:3]
for i in abs_norm_resid_top_3:
plot_lm_3.axes[0].annotate(i,
xy=(model_fitted_y[i],
model_norm_residuals_abs_sqrt[i]));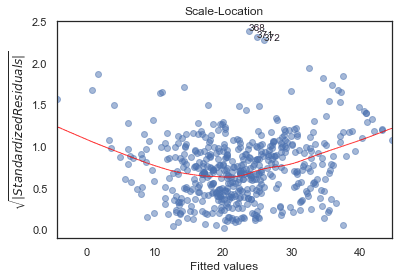
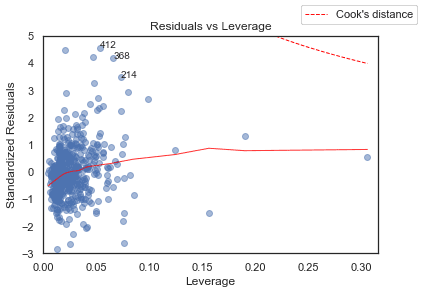
Residuals vs Leverage
plot_lm_4 = plt.figure();
plt.scatter(model_leverage, model_norm_residuals, alpha=0.5);
sns.regplot(model_leverage, model_norm_residuals,
scatter=False,
ci=False,
lowess=True,
line_kws={'color': 'red', 'lw': 1, 'alpha': 0.8});
plot_lm_4.axes[0].set_xlim(0, max(model_leverage)+0.01)
plot_lm_4.axes[0].set_ylim(-3, 5)
plot_lm_4.axes[0].set_title('Residuals vs Leverage')
plot_lm_4.axes[0].set_xlabel('Leverage')
plot_lm_4.axes[0].set_ylabel('Standardized Residuals');
# annotations
leverage_top_3 = np.flip(np.argsort(model_cooks), 0)[:3]
for i in leverage_top_3:
plot_lm_4.axes[0].annotate(i,
xy=(model_leverage[i],
model_norm_residuals[i]));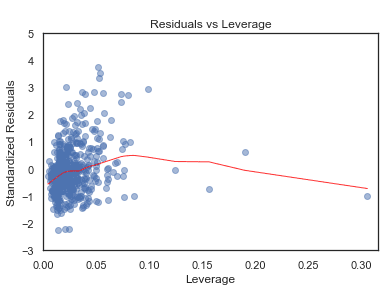
Box-Cox
from sklearn.preprocessing import PowerTransformer
from sklearn.preprocessing import MinMaxScalerdf_scaled = df.copy()
col_names= df.columns
features = df_scaled[col_names]scaler = MinMaxScaler(feature_range=(1,2))df_scaled[col_names] = scaler.fit_transform(df)power = PowerTransformer(method='box-cox')df_scaled[col_names] = power.fit_transform(df_scaled.values)df_scaled.hist(bins='auto', grid=False, figsize=(20,15), color='#86bf91', zorder=2, rwidth=0.9)
plt.show()
x = df_scaled.loc[:, df_scaled.columns != 'MEDV']
y = df_scaled['MEDV']X = sm.add_constant(X)model = sm.OLS(y, X).fit()model.summary() <class 'statsmodels.iolib.summary.Summary'>
"""
OLS Regression Results
==============================================================================
Dep. Variable: MEDV R-squared: 0.793
Model: OLS Adj. R-squared: 0.788
Method: Least Squares F-statistic: 145.3
Date: Wed, 02 Dec 2020 Prob (F-statistic): 4.97e-159
Time: 12:46:50 Log-Likelihood: -319.02
No. Observations: 506 AIC: 666.0
Df Residuals: 492 BIC: 725.2
Df Model: 13
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 2.5050 0.496 5.053 0.000 1.531 3.479
CRIM -0.0209 0.003 -6.548 0.000 -0.027 -0.015
ZN 0.0033 0.001 2.470 0.014 0.001 0.006
INDUS 0.0046 0.006 0.774 0.439 -0.007 0.016
CHAS 0.2546 0.084 3.042 0.002 0.090 0.419
NOX -1.9704 0.371 -5.310 0.000 -2.699 -1.241
RM 0.2601 0.041 6.406 0.000 0.180 0.340
AGE 1.107e-05 0.001 0.009 0.993 -0.003 0.003
DIS -0.1316 0.019 -6.790 0.000 -0.170 -0.093
RAD 0.0347 0.006 5.383 0.000 0.022 0.047
TAX -0.0015 0.000 -4.141 0.000 -0.002 -0.001
PTRATIO -0.0980 0.013 -7.713 0.000 -0.123 -0.073
B 0.0011 0.000 4.140 0.000 0.001 0.002
LSTAT -0.0687 0.005 -13.938 0.000 -0.078 -0.059
==============================================================================
Omnibus: 81.337 Durbin-Watson: 1.096
Prob(Omnibus): 0.000 Jarque-Bera (JB): 237.285
Skew: 0.765 Prob(JB): 2.98e-52
Kurtosis: 5.986 Cond. No. 1.51e+04
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.51e+04. This might indicate that there are
strong multicollinearity or other numerical problems.
"""def graph(formula, x_range, label=None):
"""
Helper function for plotting cook's distance lines
"""
x = x_range
y = formula(x)
plt.plot(x, y, label=label, lw=1, ls='--', color='red')
def diagnostic_plots(X, y, model_fit=None):
"""
Function to reproduce the 4 base plots of an OLS model in R.
---
Inputs:
X: A numpy array or pandas dataframe of the features to use in building the linear regression model
y: A numpy array or pandas series/dataframe of the target variable of the linear regression model
model_fit [optional]: a statsmodel.api.OLS model after regressing y on X. If not provided, will be
generated from X, y
"""
if not model_fit:
model_fit = sm.OLS(y, sm.add_constant(X)).fit()
# create dataframe from X, y for easier plot handling
dataframe = pd.concat([X, y], axis=1)
# model values
model_fitted_y = model_fit.fittedvalues
# model residuals
model_residuals = model_fit.resid
# normalized residuals
model_norm_residuals = model_fit.get_influence().resid_studentized_internal
# absolute squared normalized residuals
model_norm_residuals_abs_sqrt = np.sqrt(np.abs(model_norm_residuals))
# absolute residuals
model_abs_resid = np.abs(model_residuals)
# leverage, from statsmodels internals
model_leverage = model_fit.get_influence().hat_matrix_diag
# cook's distance, from statsmodels internals
model_cooks = model_fit.get_influence().cooks_distance[0]
plot_lm_1 = plt.figure()
plot_lm_1.axes[0] = sns.residplot(model_fitted_y, dataframe.columns[-1], data=dataframe,
lowess=True,
scatter_kws={'alpha': 0.5},
line_kws={'color': 'red', 'lw': 1, 'alpha': 0.8})
plot_lm_1.axes[0].set_title('Residuals vs Fitted')
plot_lm_1.axes[0].set_xlabel('Fitted values')
plot_lm_1.axes[0].set_ylabel('Residuals');
# annotations
abs_resid = model_abs_resid.sort_values(ascending=False)
abs_resid_top_3 = abs_resid[:3]
for i in abs_resid_top_3.index:
plot_lm_1.axes[0].annotate(i,
xy=(model_fitted_y[i],
model_residuals[i]));
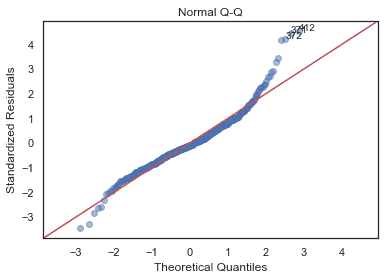
QQ = ProbPlot(model_norm_residuals)
plot_lm_2 = QQ.qqplot(line='45', alpha=0.5, color='#4C72B0', lw=1)
plot_lm_2.axes[0].set_title('Normal Q-Q')
plot_lm_2.axes[0].set_xlabel('Theoretical Quantiles')
plot_lm_2.axes[0].set_ylabel('Standardized Residuals');
# annotations
abs_norm_resid = np.flip(np.argsort(np.abs(model_norm_residuals)), 0)
abs_norm_resid_top_3 = abs_norm_resid[:3]
for r, i in enumerate(abs_norm_resid_top_3):
plot_lm_2.axes[0].annotate(i,
xy=(np.flip(QQ.theoretical_quantiles, 0)[r],
model_norm_residuals[i]));
plot_lm_3 = plt.figure()
plt.scatter(model_fitted_y, model_norm_residuals_abs_sqrt, alpha=0.5);
sns.regplot(model_fitted_y, model_norm_residuals_abs_sqrt,
scatter=False,
ci=False,
lowess=True,
line_kws={'color': 'red', 'lw': 1, 'alpha': 0.8});
plot_lm_3.axes[0].set_title('Scale-Location')
plot_lm_3.axes[0].set_xlabel('Fitted values')
plot_lm_3.axes[0].set_ylabel('$\sqrt{|Standardized Residuals|}$');
# annotations
abs_sq_norm_resid = np.flip(np.argsort(model_norm_residuals_abs_sqrt), 0)
abs_sq_norm_resid_top_3 = abs_sq_norm_resid[:3]
for i in abs_norm_resid_top_3:
plot_lm_3.axes[0].annotate(i,
xy=(model_fitted_y[i],
model_norm_residuals_abs_sqrt[i]));
plot_lm_4 = plt.figure();
plt.scatter(model_leverage, model_norm_residuals, alpha=0.5);
sns.regplot(model_leverage, model_norm_residuals,
scatter=False,
ci=False,
lowess=True,
line_kws={'color': 'red', 'lw': 1, 'alpha': 0.8});
plot_lm_4.axes[0].set_xlim(0, max(model_leverage)+0.01)
plot_lm_4.axes[0].set_ylim(-3, 5)
plot_lm_4.axes[0].set_title('Residuals vs Leverage')
plot_lm_4.axes[0].set_xlabel('Leverage')
plot_lm_4.axes[0].set_ylabel('Standardized Residuals');
# annotations
leverage_top_3 = np.flip(np.argsort(model_cooks), 0)[:3]
for i in leverage_top_3:
plot_lm_4.axes[0].annotate(i,
xy=(model_leverage[i],
model_norm_residuals[i]));
p = len(model_fit.params) # number of model parameters
graph(lambda x: np.sqrt((0.5 * p * (1 - x)) / x),
np.linspace(0.001, max(model_leverage), 50),
'Cook\'s distance') # 0.5 line
graph(lambda x: np.sqrt((1 * p * (1 - x)) / x),
np.linspace(0.001, max(model_leverage), 50)) # 1 line
plot_lm_4.legend(loc='upper right');diagnostic_plots(X, y)
Linear Regression using SKlearn:
from sklearn import linear_model#Multiple linear regression (Select single variable for simple linear regression)
X = df[['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT']]
#x = df.loc[:, df.columns != 'MEDV'] #Same as above but more convenient
#X = df[['CRIM', 'ZN']] #Omit insignificant variable
y = df['MEDV'] #Target or dependend VariableSplit Train and Test Data
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=101)Creating and Training the Model:
from sklearn.linear_model import LinearRegressionlm = LinearRegression()lm.fit(X_train,y_train) #trained model LinearRegression()Model Evaluation
lm.intercept_ 41.28149654473732lm.score(X_train,y_train) 0.7501501474315525lm.coef_ array([-7.75583711e-02, 4.20310157e-02, 9.11529473e-02, 4.13304932e+00,
-1.99765575e+01, 2.89019042e+00, 1.61533256e-02, -1.26474745e+00,
2.60170760e-01, -1.11251993e-02, -8.80555502e-01, 7.02445445e-03,
-6.43482813e-01])X.columns Index(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT'],
dtype='object')coeff_df = pd.DataFrame(lm.coef_,X.columns,columns=['Coefficient'])
coeff_df Coefficient
CRIM -0.077558
ZN 0.042031
INDUS 0.091153
CHAS 4.133049
NOX -19.976557
RM 2.890190
AGE 0.016153
DIS -1.264747
RAD 0.260171
TAX -0.011125
PTRATIO -0.880556
B 0.007024
LSTAT -0.643483Predictions from trained Model
predictions = lm.predict(X_test)
predictions array([38.76995104, 27.39271318, 16.26805601, 16.64592872, 30.5945708 ,
31.37975753, 37.68282481, 7.57986744, 33.62371472, 6.94206736,
30.00015138, 13.74184077, 16.41357803, 17.5975484 , 24.92452314,
20.61277162, 6.84027833, 32.74459645, 28.14176473, 24.87051184,
12.01460369, 19.89597528, 22.93223855, 24.84808083, 33.41944923,
18.2663553 , 32.40616206, 19.07263109, 27.85446156, 33.36724349,
20.31071184, 18.71427039, 36.3942392 , 43.97914411, 28.53636198,
22.23810379, 15.23341286, 18.4441601 , 2.99896469, 30.75373687,
23.98495287, 17.65233987, 33.49269972, 13.72450288, 17.45026475,
25.3864821 , 29.9370352 , 16.43822597, 27.0157306 , 23.23886475,
31.8958797 , 36.8917952 , 22.96758436, 18.06656811, 30.34602124,
-0.30828515, 19.8446382 , 16.6131071 , 23.63902347, 21.26225918,
29.69766593, 3.14282554, 16.86387632, 19.76329036, 9.71050797,
24.21870511, 24.27695942, 19.87071765, 17.16247142, 19.85216234,
23.74078001, 21.56791537, 23.14099313, 20.54638573, 27.77053085,
21.2590119 , 36.87579928, 8.05035628, 28.9146871 , 16.70037511,
15.70980238, 19.14484394, 29.65683713, 16.86617546, 10.15073018,
21.34814159, 21.81482232, 32.18098353, 22.24314075, 21.75449868,
12.50117018, 10.64264803, 22.59103858, 32.00987194, 5.75604165,
34.05952126, 7.04112579, 31.53788515, 9.02176123, 21.19511453,
32.37147301, 21.32823602, 27.19438339, 24.91207186, 23.08174295,
24.76969659, 24.77145042, 30.14032582, 36.63344929, 32.59298802,
23.27852444, 35.5111093 , 24.17973314, 22.05040637, 29.57566524,
26.94598149, 28.86934886, 30.98598123, 26.77898549, 28.83037557,
16.05739187, 20.89220193, 21.91047939, 36.88601261, 25.01402328,
23.53157107, 15.12274061, 5.50883218, 14.14631563, 23.87422049,
26.85906918, 33.17708597, 24.22078613, 19.60743115, 24.54377589,
26.24871922, 30.8997013 , 26.2619873 , 33.44890707, 23.05544279,
12.12838356, 35.44082938, 31.79591619, 16.5997814 , 25.17956469,
19.77417177, 20.07188943, 24.67905941, 26.64881616, 29.50609111,
16.87246772, 16.25039628, 40.96167542, 36.18058639, 22.00214486,
21.47973172, 23.48638653, 12.67663095, 20.83340172, 24.99555373,
19.27796673, 29.13806185, 40.15324017, 22.1316772 , 26.14454982,
23.02029457, 18.61562996, 30.48499643, 17.42381182, 10.92515821,
18.66294924, 33.26084439, 34.96275041, 20.74820685, 1.70547647,
18.03065088, 27.34915728, 18.06414053, 28.56520062, 24.41093319,
27.53096541, 20.55435421, 22.62919622, 37.78233999, 26.87713512,
37.38740447, 25.79142163, 14.81336505, 22.11034091, 17.09095927,
25.08768209, 35.57385009, 8.21251303, 20.29558413, 19.03028948,
26.45168363, 24.24592238, 18.52485619, 21.43469229, 35.01450733,
20.96970996, 23.6978562 , 28.08966447])plt.figure(figsize=(10,7)) # if you want to resize your plot
plt.scatter(x=y_test,y=predictions, s=30, alpha=0.7)
plt.ylabel("predictions")
plt.xlabel("y_test") Text(0.5, 0, 'y_test')
Residual Distribution
plt.figure(figsize=(10,7)) # if you want to resize your plot # residual
sns.distplot((y_test-predictions),bins=50);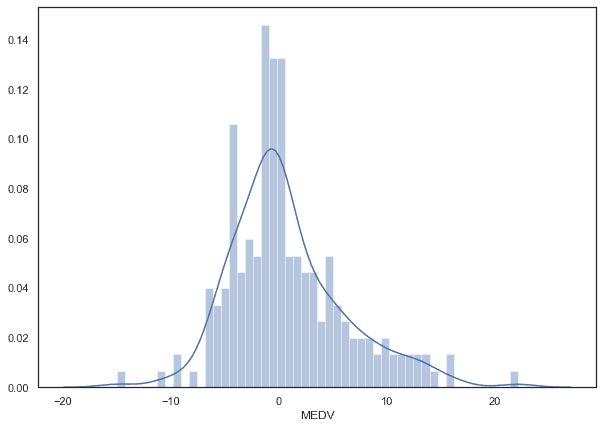
Plotting the Least Squares Line
#sns.pairplot(df, x_vars=['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
# 'PTRATIO', 'B', 'LSTAT'], y_vars='MEDV', size=7, aspect=0.7, kind='reg')Regression Evaluation Metrics
from sklearn import metricsMean Absolute Error (MAE) Mean Squared Error (MSE) Root Mean Squared Error (RMSE)
print('MAE:', metrics.mean_absolute_error(y_test, predictions))
print('MSE:', metrics.mean_squared_error(y_test, predictions))
print('RMSE:', np.sqrt(metrics.mean_squared_error(y_test, predictions)))MAE: 3.9051448026275173
MSE: 29.416365467452877
RMSE: 5.423685598138306Last updated on